这一节主要介绍一下如何进行最简单的封装,对于更加完善的实现则会放在下一节。由于我本人实现的最终版本有上千行,囿于篇幅、无法在这里进行叙述,感兴趣的观众老爷们可以参见这里
总结前文说明过的诸多子结构、不难得知我们用于封装它们的朴素网络结构至少需要实现如下这些功能:
- 加入一个 Layer
- 获取各个模型参数对应的优化器
- 协调各个子结构以实现前向传导算法和反向传播算法
接下来就看看具体的实现。先看其基本框架:
|
|
接下来实现加入 Layer 的功能。由于我们只打算进行朴素实现、所以应该对输入模型的 Layer 的格式做出一些限制以减少代码量。具体而言、我们对输入模型的 Layer 做出如下三个约束:
- 如果该 Layer 是第一次输入模型的 Layer 的话(亦即)、则要求 Layer 的
shape属性是一个二元元组,此时shape[0]即为输入数据的维度、shape[1]即为的神经元个数 - 否则(亦即)、我们要求 Layer 输入模型时的
shape属性是一元元组,其唯一的元素记录的就是该Layer的神经元个数
比如说、如果我们想设计含有如下结构的神经网络:
- 含有一层 ReLU 隐藏层,该层有 24 个神经元
- 损失函数为 SigmoidCross Entropy 的组合
那么在实现完毕后、需要能够通过如下三行代码:
|
|
来把对应的结构搭建完毕(其中 x、y 是训练集)。以下即为具体实现:
|
|
然后就需要获取各个模型参数对应的优化器并实现前向传导算法和反向传播算法了。鉴于我们实现的是朴素的版本、我们只允许用户自定义学习速率、优化器使用的算法及总的迭代次数:
|
|
这里用到了三个方法、它们的作用为:
self._init_optimizers:根据优化器的名字、学习速率和迭代次数来初始化优化器self._get_activations:进行前向传导算法self._opt:利用局部梯度和优化器来更新模型的各个参数
它们的具体实现如下:
|
|
最后就是模型的预测了,这一部分的实现非常直观易懂:
|
|
至此、一个朴素的神经网络结构就实现完了;虽说该模型有诸多不足之处,但其基本的框架和模式却都是有普适性的、且它的表现也已经相当不错。可以通过在螺旋线数据集上做几组实验来直观地感受一下这个朴素神经网络的分类能力、结果如下图所示:
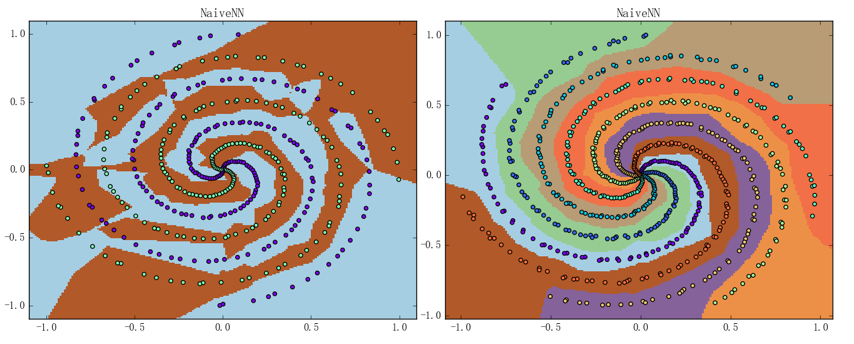
左图是 4 条螺旋线的二类分类问题、准确率为 92.75%;右图为 7 条螺旋线的七类分类问题、准确率为 100%;神经网络的结构则都是两层含 24 个神经元的 ReLU 加 SoftmaxCross Entropy 组合的这个结构,迭代次数则为 1000 次、平均训练时间分别为 0.74秒(左图)和 1.04秒(右图)。注意到虽然我们使用的螺旋线数据集的“旋转程度”比之前使用过的螺旋线数据集的都要大不少、但是神经网络的表现仍然相当不错

