有了上一篇文章的诸多准备、我们就能以之为基础实现核感知机和 SVM 了。不过需要指出的是,由于我们实现的 SVM 是一个朴素的版本、所以如果是要在实际任务中应用 SVM 的话,还是应该使用由前人开发、维护并经过长年考验的成熟的库(比如 LibSVM 等);这些库能够处理更大的数据和更多的边值情况、运行的速度也会快上很多,这是因为它们通常都使用了底层语言来实现核心算法、且在算法上也做了许多数值稳定性和数值优化的处理
核感知机的实现
|
|
可以看到代码清晰简洁,这主要得益于核感知机算法本身比较直白。我们可以先通过螺旋线数据集来大致看看它的分类能力、结果如下图所示:
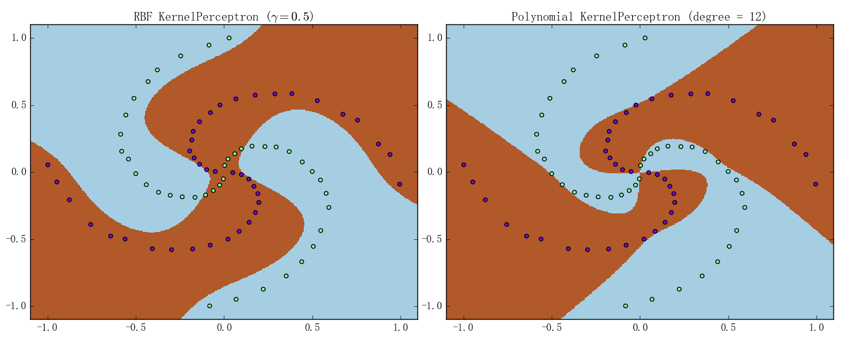
左图为 RBF 核感知机()、准确率为 90.0%;右图为多项式核感知机()、准确率为 98.75%(迭代次数都是)。虽说效果貌似还不错,但是由它们的训练曲线可以看出、训练过程其实是相当“不稳定”的:
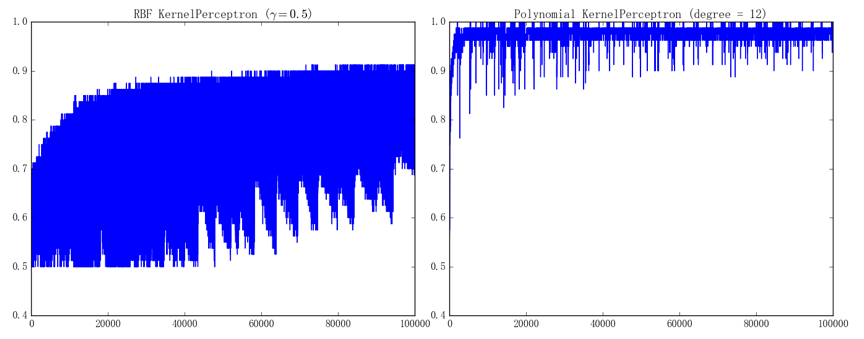
左、右图分别对应着 RBF 核感知机和多项式核感知机的训练曲线。之所以有这么大的波动、是因为我们采取的随机梯度下降每次只会进行非常局部的更新,而螺旋线数据集本身又具有比较特殊的结构,从而在直观上也能想象、模型的参数在训练的过程中很容易来回震荡。这一点在 SVM 上也会有体现、因为我们打算实现的 SMO 算法同样也是针对局部(两个变量)进行更新的
核 SVM 的实现
接下来就看看核 SVM 的实现,虽说有些繁复、但其实只是一步一步地将之前说过的算法翻译出来而已,如果能理顺算法的逻辑的话、实现本身其实并不困难:
|
|
以上就是 SMO 算法中的核心步骤,接下来只需要将它们整合进一个大框架中即可(需要指出的是,随机选取第二个变量虽说效果也不错、但效率终究还是会差上一点;不过考虑到实现的复杂度、我们还是用随机选取的方法来进行实现):
|
|
可以看到大部分代码确实只是算法的直译。同样可以先通过螺旋线数据集来大致看看核 SVM 的分类能力、结果如下图所示(图中用黑圈标注的样本点即是支持向量):
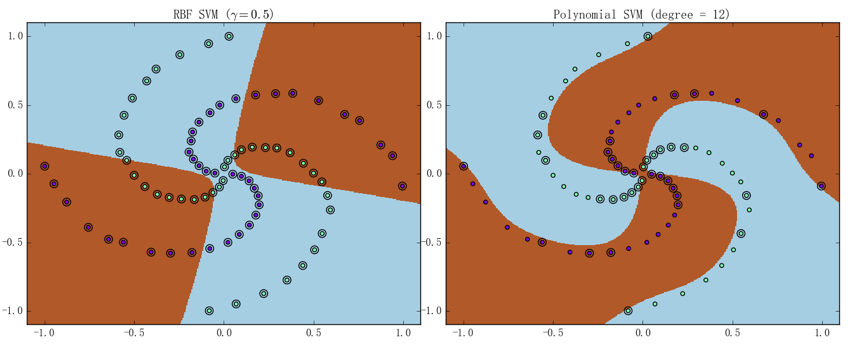
左图为 RBF 核 SVM()、迭代了 729 次即达到了停机条件(所有样本的误差都)、最终准确率为 51.25%;右图为多项式核 SVM()、迭代了 6727 次即达到了停机条件、准确率为 97.5%。它们的训练曲线如下图所示:
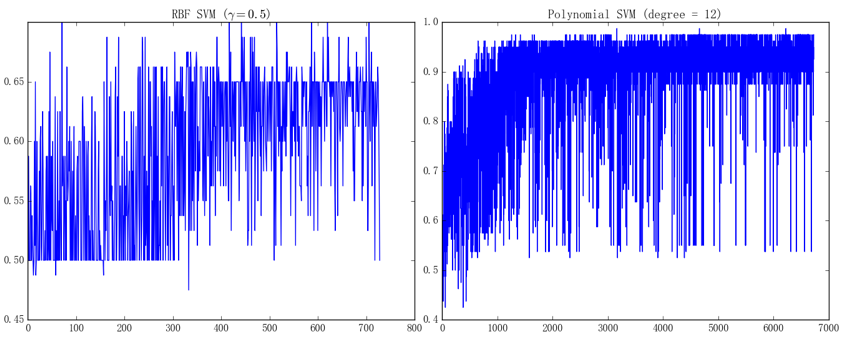
左、右图分别对应着 RBF 核 SVM 和多项式核 SVM 的训练曲线。虽说看上去似乎比核感知机的表现还要差、但这毕竟只是一个特殊的情形;事实上、即使是成熟的 SVM 库也并不是万能的。比如如果直接使用螺旋线数据集来训练 sklearn 中的、基于 LibSVM 进行实现的 SVM 模型的话、会得到如下图所示的结果:
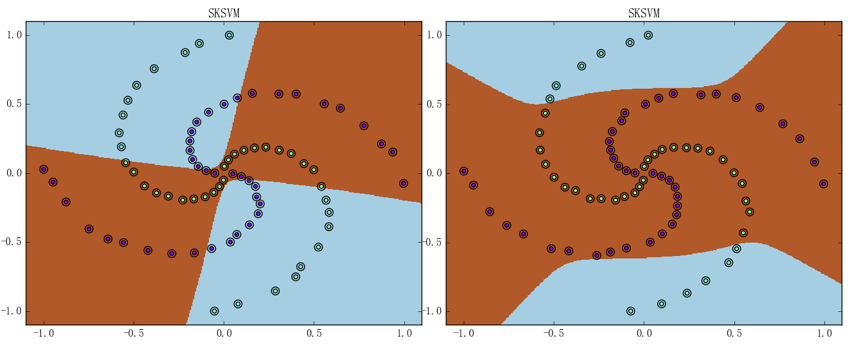
左图为 RBF 核 SVM()、最终准确率为 50.0%;右图为多项式核 SVM()、准确率为 65.0%。造成这种差异的原因在于我们实现的多项式核函数和 sklearn 中的 SVM 所使用的多项式核函数不一样,如果将我们的核函数传进去、是可以得到相似结果的
作为本篇文章的收尾,我们可以通过画出两种核模型在蘑菇数据集上的训练曲线来简单地评估一下模型在真实数据下的表现。为了说明模型的泛化能力,我们只取 100 个样本作为训练样本、并用剩余 8000 多个样本作为测试样本来检验
首先来看一下核感知机的表现:
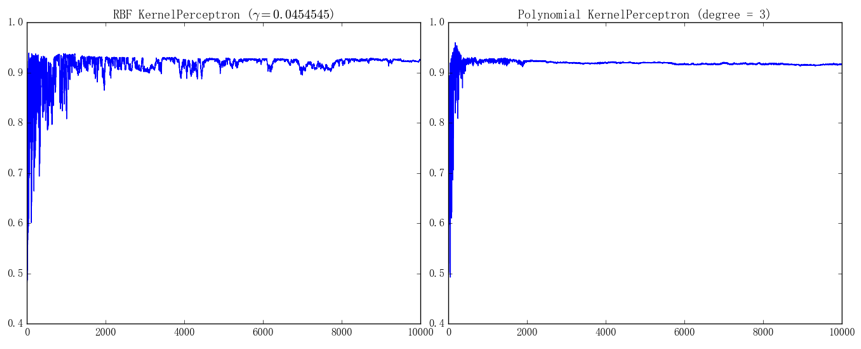
左图为 RBF 核感知机()的训练曲线、最终在测试集上的准确率为 92.53%;右图为多项式核感知机()的训练曲线、最终在测试集上的准确率为 91.59%(迭代次数都是)。由于只采用了 100 个样本训练、每次训练后的模型表现会波动得比较厉害;不过总体而言、RBF 核感知机会比多项式核感知机波动得更厉害一点
接下来看一下核 SVM 的表现:
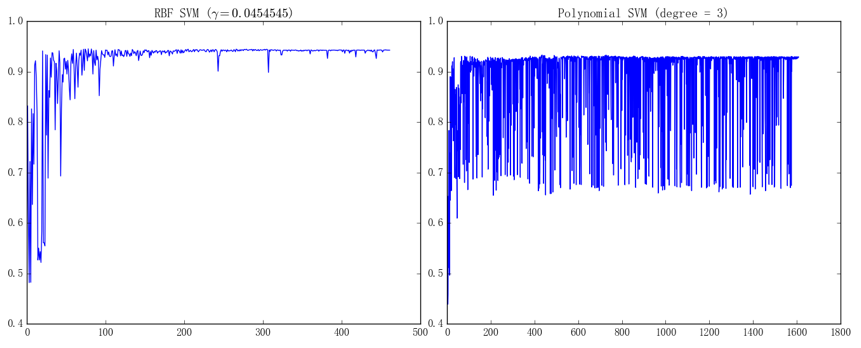
左图为 RBF 核 SVM()、迭代了 462 次即达到了停机条件、最终在测试集上的准确率为 94.29%;右图为多项式核 SVM()、迭代 1609 次即达到了停机条件、最终在测试集上的准确率为 92.96%

