本篇文章所叙述的感知机模型是我们第一次应用到梯度下降法的模型,它的算法相当简单、但其框架却相当具有代表性。虽然说感知机模型只能处理非常特殊的问题(线性可分的数据集的分类问题)、但它的思想却是值得琢磨的
线性可分性与感知机策略
在详细叙述感知机模型的原始算法之前,了解感知机适用范围和基本思想是必要的。正如前文所说,感知机只能用于给线性可分的数据集分类。其中,所谓的“线性可分性”的定义其实相当直观:对于一个数据集
其中
如果存在一个超平面能够将中的正负样本点精确地划分到的两侧、亦即:
使得
那么就称数据集是线性可分的(Linearly Separable);否则、就称线性不可分
当维数时、数据集线性可分等价于正负样本点能在二维平面上被一条直线精确划分;当时则等价于能在三维空间中被一个平面精确划分。下给出一组线性可分和一组线性不可分的例子:


从数学的角度来说,线性可分性还有一个比较直观的等价定义:正负样本点集的凸包彼此不交。所谓凸包的定义如下:若集合由个点组成:
那么的凸包即为:
比如,上述两个二维数据集的凸包将如下面两张图所示:
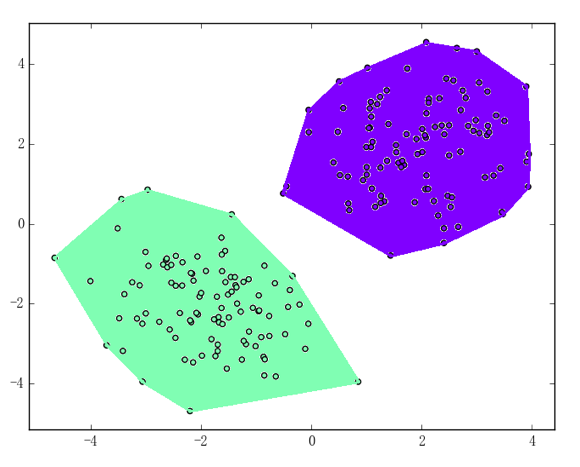
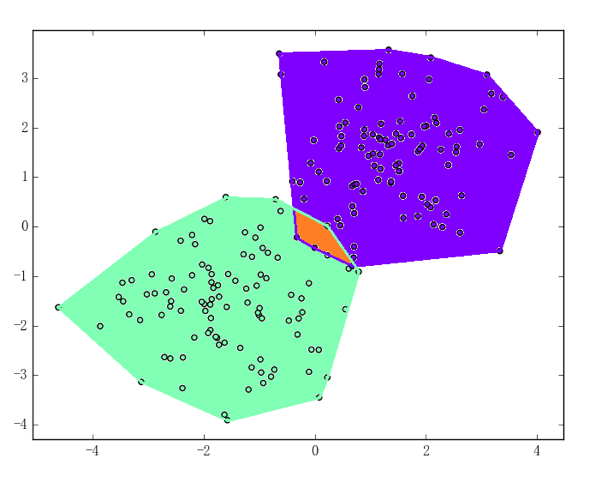
第一张图中,正负样本点集的凸包不交、所以数据集线性可分;第二张图中的橙色区域即为正负样本点集凸包的相交处、所以数据集线性不可分
该等价性的证明可以用反证法得出;由于过程不算困难且结论相当直观、所以具体的推导步骤从略
知道了线性可分性的定义之后、感知机模型的目的也就容易想到了——无非就是为了找到上文提到过的、能将线性可分数据集中的正负样本点精确划分到两侧的超平面。考虑到机器学习的共性,我们希望能将找超平面的过程转化为最小化一个损失函数的过程;感知机策略的具体表现、就在于如何定义这个损失函数上。考虑到的性质,损失函数的定义其实是很自然的:
其中是被当前感知机误分类的点集,亦即对、有:
换句话说、损失函数还可以表示为:
注意到对于样本点而言、能够相对地表示向量到分离超平面的距离,所以损失函数的几何解释即为:损失函数值所有被误分类的样本点到当前分离超平面的相对距离的总和。如果感知机能将所有样本点正确分类的话、就是空集、此时损失函数;同时,若误分类的样本点越少或误分类的样本点离当前分离超平面越近、损失函数的值就越小。是故寻找最终正确的分离超平面的过程、确实可以转化为最小化损失函数的过程,而这也正是感知机所采用的训练策略
注意:需要强调的是,所描述的“相对距离”和我们直观上的“欧氏距离”或说“几何距离”是不一样的(事实上它们之间相差了一个);相对严谨的叙述会放在从感知机到支持向量机中、这里就先按下不表
感知机算法
最小化损失函数这个过程在决策树的训练中也出现过,彼时我们采用的是一种启发式的算法——选取当前能使损失(信息的不确定性)减少最多的特征作为划分标准来划分数据。感知机算法采用的则是一种应用场景更广的方法——梯度下降法。梯度下降法的一般性定义和相关说明会放在相关数学理论中、这里我们只说一个直观:在许多情况下,损失函数是足够好的函数、从而它在每个点都能进行“求导”。求导之后我们就能得到一个损失函数增长最快的“方向”,此时我们沿反方向前进的话、就能期望损失函数以“最快的速度”减少(这也正是为何梯度下降法又叫最速下降法)
注意到在求得“方向”后、沿方向“走多远”也是需要考虑的参数。一般我们称该参数为“学习速率”或“步长”,通过调整和优化该参数的表现、常常能导出原理一致但表现迥异的算法。不过即使如此,梯度下降法的关键还是在于损失函数的“求导”。需要指出的是,梯度下降法本身还可以大致分为三种具体的算法——随机梯度下降法(Stochastic Gradient Descent,常简称为 SGD)、小批量梯度下降法(Mini-batch Gradient Descent,常简称为 MBGD)和批量梯度下降法(Batch Gradient Descent,常简称为 BGD)。这三种梯度下降法的说明、对比同样会放在相关数学理论中进行,这里只需要知道它们行为上的差别:随机梯度下降法在每个迭代中只使用一个样本来进行参数的更新、小批量梯度下降法则会同时选用多个样本来更新参数、批量梯度下降法则更是会同时选用所有样本来更新参数
注意:也有认为 SGD 即为 MBGD 的说法、所以具体的含义需要结合具体情况分析
简单起见、我们采用随机梯度下降来进行训练,此时我们需要求出损失函数在单一样本上对和的偏导数:
利用它们可以自然地写出感知机模型的随机梯度下降训练算法:
- 输入:训练数据集、迭代次数 M、学习速率,其中:
- 过程:
- 初始化参数:
- 对:
- 若(亦即没有误分类的样本点)则退出循环体
- 否则,任取中的一个样本点并利用它更新参数:
- 输出:感知机模型
其中最后一步用到的 sign 是符号函数。由于感知机算法中更新一次参数的时间开销非常小、所以通常会把迭代次数 M 设置成一个比较大的数(比如)
此外需要指出的是,虽说感知机只适用于线性可分数据集的分类、但它有个优点就是:无论学习速率是多少,只要数据集线性可分,那么上述感知机算法在 M 足够大的情况下、必然能够训练出一个使得的分离超平面(这其实就是著名的 Novikoff 定理,证明会用到比较纯粹的数学技巧、所以从略)
虽说所蕴含的梯度下降的思想并不平凡,但感知机算法单就复杂度而言、可以说是目前为止遇到过的最简单的算法了,其实现相对的也非常简单直观:
|
|
可以用之前提到过的两个二维数据集来简单评估一下我们实现的感知机模型,结果如下图所示:
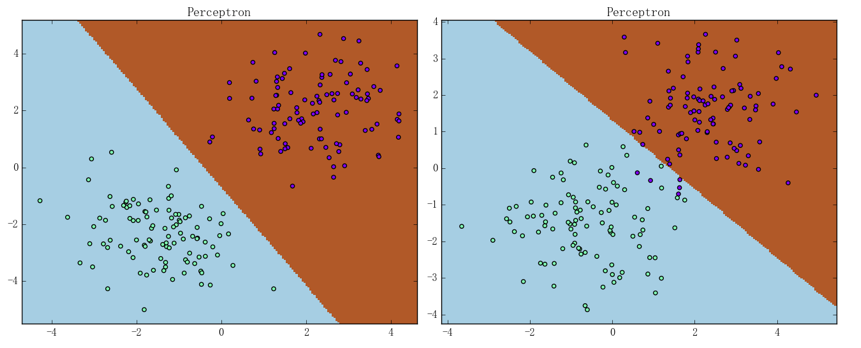
其中在线性可分的数据集上、感知机只用了一次迭代便得到了上面左图中的效果;在线性不可分的数据集上、感知机在迭代 1000 次后可以得到右图中的效果,此时正确率为 97.5%
感知机算法的对偶形式
本节将会简要介绍一个非常重要的概念:拉格朗日对偶性(Lagrange Duality);在有约束的最优化问题中,为了便于求解、我们常常会利用它来将比较原始问题转化为更好解决的对偶问题。对于特定的问题,原始算法的对偶形式也常常会有一些共性存在。比如对于感知机和后文会介绍的支持向量机来说,它们的对偶算法都会将模型的参数表示为样本点的某种线性组合、并把问题转化为求解线性组合中的各个系数
虽说感知机算法的原始形式已经非常简单,但是通过将它转化为对偶形式、我们可以比较清晰地感受到转化的过程,这有助于理解和记忆后文介绍的、较为复杂的支持向量机的对偶形式
考虑到原始算法的核心步骤为:
其中、是当前被误分类的样本点的集合;可以看见、参数的更新是完全基于样本点的。考虑到我们要将参数和表示为样本点的线性组合,一个自然的想法就是记录下在核心步骤中、各个样本点分别被利用了多少次、然后利用这个次数来将和表示出来。比如说,若设样本点一共在上述核心步骤中被利用了次、那么就有(假设初始化参数时):
如果进一步设、则有:
在此基础上,感知机算法的对偶形式就能很自然地写出来了:
- 输入:训练数据集、迭代次数 M、学习速率,其中:
- 过程:
- 初始化参数:
- 对:
- 若(亦即没有误分类的样本点)则退出循环体
- 否则,任取中的一个样本点并利用其下标更新参数:
- 输出:感知机模型
需要指出的是,在对偶形式中、样本点里面的仅以内积的形式()出现;这是一个非常重要且深刻的性质,利用它和后文将进行介绍核技巧、能够将许多算法从线性算法“升级”成为非线性算法
注意到对偶形式的训练过程常常会重复用到大量的、样本点之间的内积,我们通常会提前将样本点两两之间的内积计算出来并存储在一个矩阵中;这个矩阵就是著名的 Gram 矩阵、其数学定义即为:
这样的话,在训练过程中如果要用到相应的内积、只需从 Gram 矩阵中提取即可,这样在大多数情况下都能大大提高效率

