感知机确实能够解决线性可分数据集的分类问题,但从它的解法容易看出、感知机的解是有无穷多个的。这主要是因为它对自己的要求太低:只需对训练集中所有样本点都能正确分类即可。换句话说、感知机基本没有考虑模型的泛化能力,这就导致感知机有时会训练出如下图所示的结果:
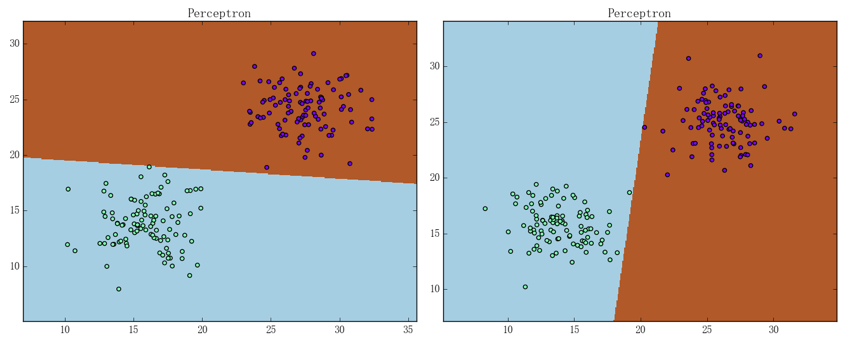
可以看出它们是不尽合理的。支持向量机(SVM)针对这一点提出了一种改进方法,本篇文章主要叙述的就是该改进的思想和具体内容
间隔最大化与线性 SVM
上图的结果之所以显得不合理、主要是因为分离超平面离正负样本点集都显得“太近”了。因此一个自然的想法就是:在训练过程中考虑上超平面到点集的距离、并努力让这个距离最大化
然而直接从集合出发定义集合到平面的距离是相对困难的、所以通常会将它转化为点到平面的距离。前文已经说过,对于样本点而言、它到超平面的相对距离即为:
这里的相对距离有一个更学术一点称谓——函数间隔(Functional Margin)。函数间隔有一个比较明显的缺陷就是、当和等比例变大或变小时,虽然超平面不会改变、但是却会随之等比例变大或变小。为解决这个问题、我们可以比较自然地定义出所谓的几何间隔(Geometric Distance):
这里的是的欧式范数。顾名思义、几何间隔描述的就是向量到超平面的几何距离(欧氏距离),它不会随和的等比例变化而变化、是相对稳定且直观意义优良的距离的定义方法。SVM 在训练过程中所引入的也正是各个样本点到当前分离超平面的几何距离,结合前文所说的“努力让超平面到点集的距离最大化”、SVM 算法就可以比较自然地叙述为:最大化(几何间隔)、使得:
考虑到几何间隔和函数间隔之间的转换关系、该问题可以等价为:最大化、使得:
可以发现函数间隔的取值其实对该优化问题的解没有影响。这是因为当变成时、和也会相应地变成和(在超平面不变的情况下),此时和不等式约束都没有变、所以对优化问题确实没有影响。这样的话我们就能不妨设、从而优化问题就可以转换为:最大化、使得:
易知该优化问题又能转化为:最小化、使得:
这就是 SVM 算法的最原始的形式。可以证明,只要训练集线性可分、那么 SVM 算法对应的这个优化问题的解就存在且唯一;其中存在性的证明相对直观、唯一性的证明需要用到反证法和一些数学上的技巧,细节从略
假设该优化问题的解为和,我们通常称超平面:
为的最大硬间隔分离超平面。之所以称它为“硬间隔”的理由会在后文叙述,这里暂时按下不表。需要指出的是,考虑到优化问题中的不等式约束、易知在超平面
和超平面
之间、是没有任何中的样本点的。不过在和上、确实有可能有样本点。我们通常称和为间隔边界、称其上的某些点为支持向量
注意:也有间隔边界上的样本点全是支持向量的说法,本书采用的支持向量的定义将更“苛刻”一些,具体细节会在 SVM 算法的对偶形式的叙述中讲到
以上的叙述比较完整地说明了 SVM 如何应用于线性可分的数据集,接下来我们就看看如何将这种思想拓展到线性不可分数据集的分类之上。事实上,由于单用超平面的话、甚至连对线性不可分数据集正确分类都做不到,更不用提在此之上的将(硬)间隔最大化的问题了;但是考虑到间隔最大化的思想、我们可以做一定的“妥协”:将“硬”间隔转化为更加普适的“软”间隔。从数学的角度来说,这等价于将不等式约束放宽:
其中的通常被称为“松弛变量”,它需要满足。当然、这个约束的放宽并不是没有代价的,我们要在需要最小化的上加进一个“惩罚项”来“惩罚”。换句话说,我们需要最小化的项将变为:
式中即为损失函数、损失函数中的()通常被称为“惩罚因子”,它描述了对松弛变量的“惩罚力度”:越大意味着最终的 SVM 模型越不能容忍误分类的点,越小则反之
综上所述、SVM 算法对应的优化问题可以拓展为:最小化、使得:
其中
可以证明该优化问题的解存在、且的解唯一但的解不唯一,证明细节从略。同时参照感知机算法、自然希望能够写出使用随机梯度下降来训练软间隔最大化 SVM 的算法;但是注意到表达式中的是有约束的(需要不小于 0)、所以直接对其进行随机梯度下降存在一定的困难。为了将问题近似转化为无约束最优化问题、我们可以引入 Hinge 损失,其定义很简单:
其中。换句话说,只有在模型作出足够肯定的正确的预测时、Hinge 损失才为 0;否则即使模型作出了正确的预测、Hinge 损失还是有可能给予模型一个惩罚
利用 Hinge 损失、我们可以把损失函数写成:
并通过最小化来求解上述 SVM 算法对应的最优化问题
注意:最小化和上文最优化问题的等价性可能并不太显然,但是通过对比损失函数及逐条比对约束条件、完成等价性证明不算太困难(比如直接令)
由于我们想要写出随机梯度下降的算法、所以求出在单一样本上对和的偏导数是有必要的:
有了这两个偏导数之后,模仿感知机算法、我们就可以比较轻松地写出软间隔最大化 SVM 的随机梯度下降训练算法:
- 输入:训练数据集、迭代次数 M、惩罚因子、学习速率,其中:
- 过程:
- 初始化参数:
- 对:
- 算出误差向量、其中:
- 取出误差最大的一项:
- 若则直接退出循环体、否则取对应的样本来进行随机梯度下降
- 输出:线性 SVM 模型
需要指出的是,虽然算法看上去差不多、内核也都是随机梯度下降,但其实在感知机模型对学习速率不敏感的同时、线性 SVM 对学习速率是相当敏感的。由前文提到过的 Novikoff 定理和凸优化相关理论可以从理论上解释这个现象,囿于篇幅、这里就不展开叙述了
由于上述线性 SVM 算法的实现和感知机算法的实现几乎一致、所以我们就略去对线性 SVM 实现的详细说明;观众老爷们可以参照感知机的代码来尝试进行实现、我个人实现的版本则可以参见这里
可以通过二维线性可分数据集来简单直观地感受一下感知机和线性 SVM 的区别、结果如下图所示:
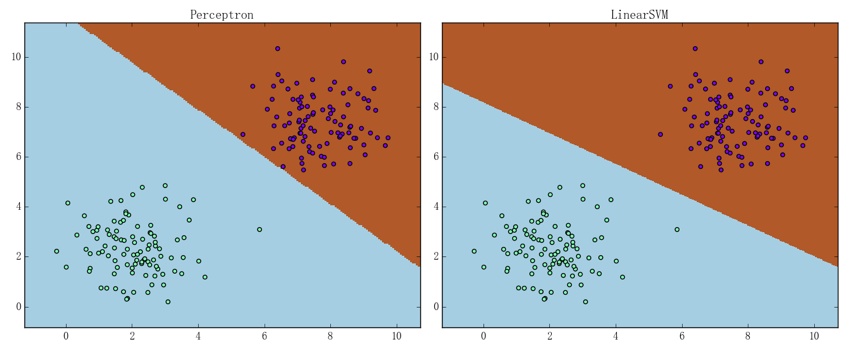
其中左、右图分别为感知机和线性 SVM 的表现,可以看出线性 SVM 要更合理
SVM 算法的对偶形式
与感知机类似、SVM 算法也是存在着对偶形式,不过这个转化的过程会比感知机那里的转化过程复杂不少。具体的推导步骤会放在相关数学理论中、这里我们就直接看结果:
- 硬间隔最大化的对偶形式 使得对、都有:
- 软间隔最大化的对偶形式 使得对、都有:
可以看到它们彼此之间相似度非常高、且转化的过程和感知机的转化过程也多少有些相似。同样的,由于对偶形式中样本点仅以内积的形式出现、我们通常会先把 Gram 矩阵算出来。现我们假设对偶形式的解为、那么就有:
其中的表达式和感知机中的表达式一致、表达式中出现的 j 是满足的下标(用反证法可以证明这种 j 必然存在,细节从略)
在有了对偶形式之后、我们就可以叙述支持向量的一个比较“苛刻”的定义了:假设支持向量的集合为、那么
- 在硬间隔最大化 SVM 中:
- 在软间隔最大化 SVM 中:
其中在软间隔最大化 SVM 里,由于本身其实是由约束条件规定的、所以可以把上述两式统一写成:
我们可以通过下图来直观认知何谓支持向量:
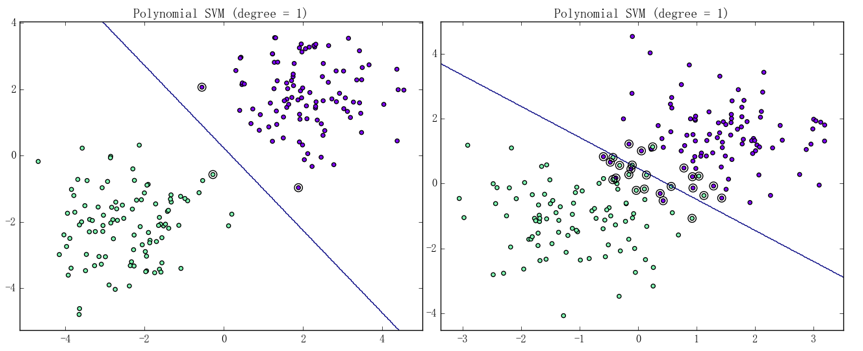
图中的线段即为决策边界、被一个黑色圆圈给圈住的样本点即为支持向量,左图为线性可分数据集上的情况、右图为线性不可分数据集上的情况
此外,说明和是如何定出各个样本点和间隔边界、分离超平面之间的位置关系是有必要的,它能加深我们对对偶形式求解过程中涉及到的 KKT 条件的理解与记忆(KKT 条件的相关定义会在相关数学理论中讲到)。具体而言:
- 若,那么被正确分类且不在间隔边界上、又或被正确分类且在间隔边界上但不是支持向量
- 若,那么就有、亦即落在间隔边界上且为支持向量
- 若,那么:
- 若、则落在间隔边界上且为支持向量
- 若、则被正确分类且落在间隔边界和分离超平面之间
- 若、则落在分离超平面上
- 若、则被错误分类
由此可知、其实刻画了到相应间隔边界的函数间隔。换句话说、即是到间隔边间的距离(几何间隔)
SVM 的训练
前文曾经提过、原始算法的对偶形式通常能将问题简化;虽然这点在感知机算法上没有太多体现,但是对于 SVM 来说,由于它的应用场景更为广泛、在许多问题的提法下转化成对偶形式的意义将非常重大。目前已经有许多针对 SVM 的成熟算法,本书拟介绍的是其中由 Platt 在 1998 年提出的、针对对偶问题求解的序列最小最优化算法(SMO)。本篇文章主要介绍 SMO 的思路和大概步骤,详细的叙述会在下一篇文章介绍完核技巧后进行
SMO 是一种启发式算法,其主要手段是在每次迭代中专注于只有两个变量的优问题以期望在可以接受的时间内得到一个较优解。具体而言、SMO 要解决的是软间隔最大化 SVM 的对偶问题:
使得对、都有:
解决方案是在循环体中不断针对两个变量构造二次规划、并通过求出其解析解来优化原始的对偶问题。大致步骤如下:
- 考察所有变量()及对应的样本点()满足 KKT 条件的情况
- 若所有变量及对应样本在容许误差内都满足 KKT 条件,则退出循环体、完成训练
- 否则、通过如下步骤选出两个变量来构造新的规划问题:
- 选出违反 KKT 条件最严重的样本点、以其对应的变量作为第一个变量
- 第二个变量的选取有一种比较繁复且高效的方法,但对于一个朴素的实现而言、第二个变量即使随机选取也无不可
- 将上述步骤选出的变量以外的变量固定、仅针对这两个变量进行最优化。易知此时问题转化为了求二次函数的极大值、从而能简单地得到解析解
这里仅简要说明一下 SVM 对偶算法中的 KKT 条件,详细的陈列则会放在相关数学理论中。具体而言、及其对应样本的 KKT 条件为:
所谓违反 KKT 条件最严重的样本点的定义也有许多种、其中一种简单有效的定义为:
- 计算“损失向量”、其中:
- 将损失向量复制三份(、、)并分情况将相应位置的损失置为 0。具体而言:
- 将或对应的置为 0
- 将或或对应的置为 0
- 将或对应的置为 0
- 将三份损失向量相加并取损失最大的样本对应的作为SMO的第一个变量、亦即:
在后面 SVM 的朴素实现中、我们打算采用的正是这种定义

