在神经网络模型中有一类特殊的 Layer 结构——它们不会独立地存在、而会“依附”在某个 Layer 之后以实现某种特定的功能。一般我们会称这种特殊的 Layer 结构为附加层(SubLayer)
参数的更新
我们之前曾简单地描述过如何使用随机梯度下降来更新参数,本文则主要会介绍一些应用得更多、效果更好的算法。正如上个系列最后所提及的,这些梯度下降的拓展算法从思想上来说和梯度下降法类似、区别则可以简练地概括如下两点:
- 更新方向不是简单地取为梯度
- 学习速率不是简单地取为常值
虽然我们不会深入地叙述这些算法背后复杂的数学基础、但我们会对每种算法都提供一些直观的解释。需要指出的是、这些算法都是利用局部梯度来获得一个更好的“梯度”、从而使得“梯度下降”变得更优
朴素的网络结构
这一节主要介绍一下如何进行最简单的封装,对于更加完善的实现则会放在下一节。由于我本人实现的最终版本有上千行,囿于篇幅、无法在这里进行叙述,感兴趣的观众老爷们可以参见这里
总结前文说明过的诸多子结构、不难得知我们用于封装它们的朴素网络结构至少需要实现如下这些功能:
- 加入一个 Layer
- 获取各个模型参数对应的优化器
- 协调各个子结构以实现前向传导算法和反向传播算法
“大数据”下的网络结构
本文标题处的“大数据”打上了引号,是因为我们所要讨论的不是当今十分火热的、真正的大数据问题、而是讨论当问题规模“相当大”时应该如何处理。我们虽然在上篇文章中实现了一个切实可用的神经网络、但它确实显得过于朴实。本文会说明如何在这个朴实模型的基础上进行拓展,这些拓展的手法不单适用于神经网络、还适用于诸多旨在解决现实生活中规模相对较大的任务的模型
相关数学理论
本文会叙述之前没有解决的纯数学问题,虽然它们仅会涉及到求导相关的知识、但是仍然具有一定难度
“神经网络”小结
- 神经网络的基本单位是层(Layer)、它是一个非常强大的多分类模型
- 神经网络的每一层()都会有一个激活函数、它是模型的非线性扭曲力
- 神经网络通过权值矩阵和偏置量来连接相邻两层、,其中能将结果从原来的维度空间线性映射到新的维度空间、则能打破对称性
- 神经网络通过前向传导算法获取各层的激活值、通过输出层的激活值和损失函数来做决策并获得损失、通过反向传播算法算出各个 Layer 的局部梯度并用各种优化器更新参数
- 合理利用一些特殊的层结构能使模型表现提升
- 当任务规模较大时、就需要考虑内存等诸多和算法无关的问题了
支持向量机综述
目前为止讲过的模型中,朴素贝叶斯模型属于生成模型:它的训练过程其实很难称之为“训练”——毕竟它只是对输入的训练数据集进行了若干“计数”的操作;决策树模型的训练过程虽然确实有一些训练的意思在里面,但其本质——各种信息不确定性的度量仍然脱不出“计数”的范畴。换句话说,朴素贝叶斯和决策树的核心步骤似乎都只是“计数”而已。随机森林和 AdaBoost 自不用提,它们都只是将已有的模型进行集成、其本身的训练过程可谓不是主体
然而我们都知道、机器学习当然不只是“计数”那么简单的一回事。因此我们拟在本系列及以后的系列中介绍另一大类训练方法——梯度下降法(Gradient Decent;有时我们也称之为最速下降法(Steepest Descent))。就本系列而言,我们会先介绍一个比较简易的、应用到了梯度下降法的模型——感知机(Perceptron),然后我们会介绍一个思想和感知机类似、但是应用场景更加广泛的模型——支持向量机(Support Vector Machine,常简称为SVM)
以下是目录:
需要指出的是、本系列的前三篇文章讨论的都是二类分类问题,回归问题和把二类算法拓展成多类算法的手段会放在多分类与支持向量回归中进行简要介绍(注意虽然我们上一个系列叙述 AdaBoost 算法时同样也只针对二类分类问题进行了说明、但是应用多分类与支持向量回归中的内容是可以将上一个系列涉及到的的诸多 AdaBoost 二分类模型推广成多分类模型的)
感知机模型
本篇文章所叙述的感知机模型是我们第一次应用到梯度下降法的模型,它的算法相当简单、但其框架却相当具有代表性。虽然说感知机模型只能处理非常特殊的问题(线性可分的数据集的分类问题)、但它的思想却是值得琢磨的
从感知机到支持向量机
感知机确实能够解决线性可分数据集的分类问题,但从它的解法容易看出、感知机的解是有无穷多个的。这主要是因为它对自己的要求太低:只需对训练集中所有样本点都能正确分类即可。换句话说、感知机基本没有考虑模型的泛化能力,这就导致感知机有时会训练出如下图所示的结果:
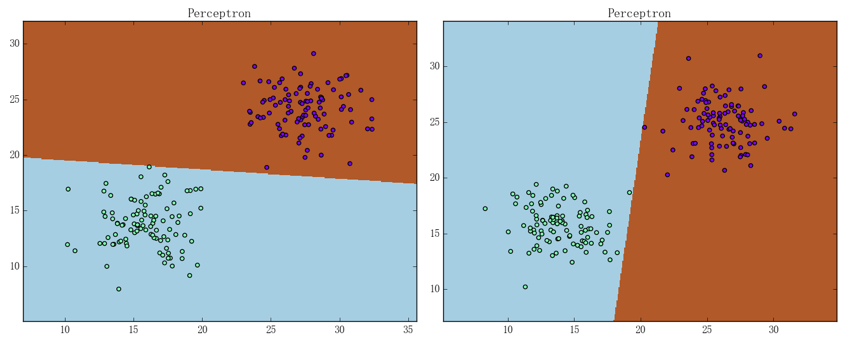
可以看出它们是不尽合理的。支持向量机(SVM)针对这一点提出了一种改进方法,本篇文章主要叙述的就是该改进的思想和具体内容
从线性到非线性
前文已经提过,由于对偶形式中的样本点仅以内积的形式出现、所以利用核技巧能将线性算法“升级”为非线性算法。有一个与核技巧(Kernel Trick)类似的概念叫核方法(Kernel Method),这两者的区别可以简单地从字面意思去认知:当我们提及核方法(Method)时、我们比较注重它背后的原理;当我们提及核技巧(Trick)时、我们更注重它实际的应用。考虑到本书的主旨、我们还是选择了核技巧这一说法
注意:以上关于核技巧和核方法这两个名词的区分不是一种共识、而是我个人为了简化问题而作的一种形象的说明,所以切忌将其作为严谨的叙述